优质题库建设之题目知识点标签自动挖掘介绍
作者:PL
说明:原文为芥末堆约稿,稍作精简,把部分科普的原理部分减掉,以问题分析为主,做一分享。
1. 在线教育与题库建设的背景
大数据和数据挖掘对于互联网教育是至关重要的,我们今天集中在一个具体的点上来展开和揭示这一点,这个点就是题库建设中的知识点标签挖掘。
在整个教育的实施过程,尤其是备、讲、练、测各个环节,今天都已经有互联网教育产品在尝试,而其中练和测,都是以题库建设为最重要的基石。题库整体设计的合理性,以及质量,是这一类互联网教育产品成败的关键。而业内的同学都知道,题库建设,又是最耗费人力物力财力的,既是苦活累活又是对教育的理解、技术能力的把握有极高要求的活。
具体而言,在题库建设过程中,并不是简单的数量的堆积,如果不考虑地区差异、应试要求不同和实效性等因素,K12阶段一个学科一个学段以千规模知识点、一个知识点以几十道题目为例进行估计,那么一个学科优质题库的规模为十万规模,而有同学似乎说应该很容易可以凑齐这么多、甚至百万规模——但是,优质题库除了题目质量,以及对教育内容(教材)的匹配度之外,还有两个根本性问题,其一是解析书写,其二是知识体系构建和知识点标签标注。若没有对这些核心因素的优化,题库很容易构建成一个普通或垃圾题库,对于教育产品应用和用户而言没有任何价值,甚至是有害的。而就是对于这些因素的优化,导致了优质题库的建设门槛,以及极高的成本。
所以,对题目的知识点标签的标注,以及知识体系的构建,是优质题库建设过程中最为核心的问题之一。
2. 题目需要什么样的知识点
在考虑这个问题的解决方案的时候,我们首先要考虑的是,我们需要什么样的知识体系和知识点标签。这个问题并不是很容易回答。
首先在教材和教学大纲中,以及各种教辅中,会有各种对“知识点”的描述,例如英语中的语法,以及词汇等,例如数学中的知识点,如函数、定义域、值域或解析式等,有直接的概念,也有方法的应用,有专题的抽象,也有相似解法的巧妙汇总,等等——总而言之,这并没有一种标准的体系,就其名称、内涵、粒度、层级,乃至所谓知识点之间的关系或联系,出自各种来源可能是千差万别的。这里既需要教育专家的高屋建瓴,也需要一线教师的灵活经验。
其次,作为数据挖掘的任务而言,我们会关心——就标签集合而言,这是一个封闭集还是一个开放集,同时,我们会关心一个“知识点”标签,是一个分类概念还是一个关键词(或者是关键词的组合,短语搭配)。这个定义的明确,对于数据挖掘的问题定义十分关键,也基本决定了后面的方案的选择。但这个明确,不仅要考虑教学意义,同时需要考虑产品对于知识点标签的使用方式,尤其是后者,可能是更加重要的因素。
举例而言,如果题库用于老师或者教研员辅助组卷,知识点标签作为导航或过滤使用,最好是通用的、概念明确的分类概念标签,加之以自由query来组合使用,这种场景需要一个精准明确的大粒度分类体系和标签集合,层级不需要很多。如果用于学生的自学推题,并显性化分析报告,那么知识点的标签应该要能够描述题目测验的核心知识点、方法或思路,要能够区分对于学生的能力要求点,这样才能构建更为强大的用户模型和推荐引擎,同时报告也方便针对性分析和理解——这个时候需要采取的分类体系和标签集合,其知识点的粒度要足够精细,而知识体系的层级就会大很多,同时,“知识点”即使不是标准体系,也需要大多数的老师和学生认可或一定的使用度。但如果这个知识体系和知识点标签,仅仅是作为系统内部匹配使用,对于用户而言是不可见的,那么使用关键词标签,使用一个开放的(或标准模糊的)标签集合,也是没有任何问题的。
就这三种例子而言,可能都是适合某种教育产品需要的;但对于知识点标签的挖掘而言,其技术的选择则是差异极大的。所以这不是一个简单可以决定的问题,需要和教育内容团队、产品团队仔细的分析确定。
3. 对问题的定义
在本文的介绍中,我们选择其中之一的应用方式作为应用场景,也就是说,我们假设要挖掘的知识点标签,是用于题目的推荐和分析报告。这个时候是最为复杂的一种,一个知识体系大概有四到七级,千规模的知识点数量,对于教研团队和技术团队,都有较大的挑战。
对于数据挖掘而言,这是一个分类任务,具体一点而言,主要是依据题目短文本信息进行层次化分类的任务。在这个任务中,我们需要使用到最基础的技术是自然语言处理和机器学习,通俗一点说,就是我们通过对大量人工标注好的题目文本和知识点标签结果(也称为训练语料)的学习——通过自然语言处理的技术获取题目文本的特征,通过机器学习来得到分类模型——从而使得我们的系统具有了自动做知识点分类的能力。一般的分类问题的基本定义如下:
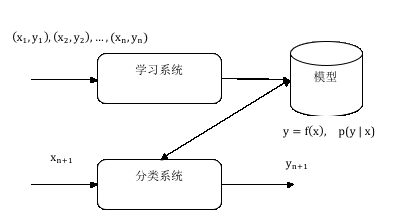
图1 分类问题的定义
在这个定义中,是待分类对象,对我们而言就是一道题目,是分类结果,对我们而言也就是一个知识点标签。学习系统的输入就是一组训练语料,即n道已经标注好的题目及其对应的知识点标签;学习系统依据这个数据经验,训练出(或学习出)一个模型,这个模型可以是函数表达形式y=f(x),也可以是概率表达形式p(y|x),这个就是学习系统的输出。基于学习系统的分类模型,分类系统就可以做预测,即输入一道新的题目,分类系统自动识别其最可能的分类结果。
通过对问题的定义,我们基本可以对这个任务做出拆解,得到类似于如下的子任务:
| 标号 | 任务名称 | 说明 |
| 1 | 分类体系(知识体系)构建 | 主要目标是建立起满足应用需求的知识体系,且,这个知识体系本身要满足分类概念的合理性,也就是说,一个知识点概念要足够的内聚,与其兄弟节点要有较明确的边界和区分度。如果知识体系不满足后一个要求,则机器学习分类是很难做出好的效果的。 |
| 2 | 分类语料构建(训练题目标注) | 主要目标是为分类体系的每一个节点,人工标注出足够多的训练语料,也就是题目。因为一个知识体系常常比较大,这个分类语料的标注工作量也往往比较大。而且,训练语料的质量(包括标注知识点的准确度、语料库平衡性等等)是后续分类效果好坏的另一个重要前提条件。在实际工程中,构建好的训练语料往往是一个有挑战的工作,因工作量关系也可能需要迭代构建。 |
| 3 | 训练分类模型,学习系统研发 | 这个过程主要目标是训练出分类模型,也就是我们机器学习系统研发最为核心的一个过程。对题目知识点标签自动挖掘而言,就是需要对上面的训练语料库,做特征分析和选择,依据某个算法学习一个分类模型,并通过一些技术手段选择一个较优化的模型输出。 |
| 4 | 做分类预测,分类系统研发 | 基于已经训练好的分类模型,可以较快的完成预测模块——分类系统的研发。但对于我们知识点标签自动挖掘而言,这里有一个相对复杂的地方,那就是我们的任务不是一个二分类任务,而是一个有庞大体系的层次化分类,预测系统也就相对复杂。另外,在工程实现时,为了优化效果,基于分类结果的一些后置处理策略,如ranking或聚合处理等,也是有一定复杂度的。 |
| 5 | 分类效果评测,迭代优化 | 如果1-4完成算是一轮研发迭代的话,那么分类效果评测(主要是通过准确率和召回率指标来衡量)就是承前启后的一个重要工作,我们通过评测来确定效果,并进一步分析语料库、特征、模型、预测过程中存在的问题,甚至是分类体系的问题,依据问题对准确率和召回率的影响面进行排序,启动优化迭代过程。 |
通过这样一个任务的拆解和说明,大家可以看出我们对于整个项目的安排,以及其中的技术关键点。这些关键点是在大量实践经验基础上总结出来的,分享出来也期望能够对技术类读者推动自己的工作有所帮助。
[具体一个机器学习模型原理的例子介绍省略]
4. 知识点标签分类的挑战
上面我们说,这个任务是非常复杂的,除了任务拆解中提到的问题和关键点,我们再次强调指出三个问题。这三个问题会对效果优化至关重要。
首先,题库中题目的文本是一个垂直领域的短文本,尤其是K12题库中的题目,其文本信息都不是很长,而且,题目中有大量的新词,有大量的信息是解析式、公式、特殊表达的信息,这对在题库的数据清洗和特征选择是极大的挑战。因为很多信息不仅蕴含在关键词中,尤其是理科题目,非关键词的文本信息中也有大量的信息,对于这些信息的处理是非常繁琐的。除了这些问题之外,还有一些题目有丰富的图片信息(如理科中函数图像、几何图形、物理化学实验等),一些题目有语音信息(如听力),这些富媒体信息中也可能包含了知识点分类的关键内容,但对于它们的处理,对于团队的技术积累和要求则是更高的。
其次,我们说这个分类任务是一个层次化分类的任务,它就会带来两个问题,一个是级联的错误放大,因为每一个分类器都有一定的准确率和召回率,导致我们在叶子节点做分类时,效果有极大的影响;其次,应用要求分类体系非常的精细,前面我们说,分类体系可能是四到七级,千规模的分类节点,这个时候分类体系的节点之间的区别度往往是一个很大的问题,表现在语料库中的题目层面,即它们分属不同兄弟节点但文本表达却有很高的相似性,会给分类模型带来很大的困扰。
第三个问题是,分类体系及知识点的合理性,很大程度上是和应用有关的,在我们这个场景,是和推题的推荐系统相关的。虽然我们会评价分类的准确率、召回率,但毕竟这只是技术评价指标,而不是业务目标。基于知识体系来刻画的用户模型和推荐引擎,对于用户的练习效果和教育效果是否真的好,这是一个周期非常长、过程非常复杂的度量。业务效果反射弧超长,这也是这个任务极大的一个问题。
这三个问题放在这里,是对我们团队的一个很大的考验。所以说,大数据和数据挖掘对互联网教育虽然是很重要的,但也是极有挑战的一个工作,需要很好的团队、很强的创新性人才的投入。好在这个方向的魅力是如此之大,吸引了很多有志之士。
5. 做大数据和数据挖掘类项目的关键点
经过上面的介绍,相信我们的读者对优质题库建设中知识点标签自动挖掘有一个相对深入的了解。我们最后做一个点睛,描述一下我们对这一类项目或方向的感触,期望能够给到大家借鉴。
这个方向的项目,有两个最大的基石,其一是对用户和产品价值的把握,也就是说,任何的挖掘技术,需要充分考虑清楚应用对它们的核心诉求;其二就是对于数据和技术,要有专业的团队和人才梯队,要能够快速上手也能够找到问题的关键点。否则的话,这一类项目是最容易失败的。在项目管理层面,这一类项目有较强的探索性,不同于功能性项目,需要做区别化的项目管理,而在团队层面,最好能够是跨越互联网和教育的融合基因,数据挖掘团队和产品团队、教师团队有紧密的、心有灵犀的默契与合作。
这些,都是技术之外不可或缺的。期望大家有所收获,感谢。